【源码解析】Java8-HashMap
函数构造
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19Map hashMap = new HashMap();
//常量
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}HashMap构造方法中只赋值了负载因子,再看一下HashMap的成员变量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26transient Node<K,V>[] table;
/**
* Holds cached entrySet(). Note that AbstractMap fields are used
* for keySet() and values().
*/
transient Set<Map.Entry<K,V>> entrySet;
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
/**
* The next size value at which to resize (capacity * load factor).
*
* @serial
*/
int threshold;
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;在这里面又看到了Node数组,这个和LinkedList的有些不一样,来看一下代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
//这里的key,value用来存put中的key和value
final K key;
V value;
//next来标记下一个元素
Node<K,V> next;
//构造函数
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}当执行完Map hashMap = new HashMap();后,在内存中的表现如下图:
新增元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46hashMap.put(1,"a");
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}这个put方法看起来有点复杂,我们一点点来分析:
1
2
3
4
5
6
7
8//从put(key,value)来调用putVal方法,其中key先做hash运算
putVal(hash(key), key, value, false, true);
static final int hash(Object key) {
int h;
//key.hashCode()这就是为啥重写equals方法的时候一定要重写hashCode的原因,因为key是基于此对象的hashCode来处理的
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}进来putVal方法:
1
2
3
4
5final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict)
Node<K,V>[] tab; Node<K,V> p; int n, i;
//第一次插入元素,此时table是null所以此判断成立,然后,进行resize这个函数有点复杂,先略过,第一次插入元素和ArrayList一样懒加载分配一个默认容量的即16的一个Node数组
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;然后继续执行代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15//其中 i = (n - 1) & hash 其中n为数组的容量,刚开始是16,&按位与转换成二进制后两边都为真才为真,所以,i的值不会大于 n-1
//如果当前位置为null的话,调用
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
//next设为空了
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}此时内存中位置如图
如果i这个位置有值了,这时候就会有冲突了,则会走else中的内容,代码有点多,我们慢慢分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36Node<K,V> e; K k;
//p在这里被赋值if ((p = tab[i = (n - 1) & hash]) == null),值为当前坑的值,如果当前坑的hash值和传来的hash值一样,并且key值也equals则说明值相等,直接赋值给e
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果现在已经是一个TreeNode了,走这里,待会再分析
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//如果是当前坑的第二个元素,则走这里
else {
//开始循环
for (int binCount = 0; ; ++binCount) {
//当前坑的list的最后一个元素,即p.next为空,则赋值给e
if ((e = p.next) == null) {
//把当前值赋值给当前坑的next
p.next = newNode(hash, key, value, null);
//static final int TREEIFY_THRESHOLD = 8;如果当前坑的链表长度到8时要开始把链表转化为红黑树来处理,先略过,待我学习红黑树知识后再来看这块,从此,这个坑的链表就不走这里了,开始走putTreeVal
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//如果要新增的值和原来的值相等的话则覆盖掉原来的值
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//元素重复了走这里
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}等一切尘埃落定后,还有一些后续操作
1
2
3
4
5
6
7++modCount;
//threshold = 容量默认16 * 负载因子0.75
if (++size > threshold)
resize();
//这里执行不会有什么操作
afterNodeInsertion(evict);
return null;Resize操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93final Node<K,V>[] resize() {
//把当前table的值赋值变成了老table
Node<K,V>[] oldTab = table;
//当前容量变成老容量
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//threshold变成老threshold
int oldThr = threshold;
int newCap, newThr = 0;
//如果大于0说明之前是有容量的
if (oldCap > 0) {
//如果之前的容量大于最大容量,给threshold赋一个最大值就可以了
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//老容量扩大2倍为新容量,如果老容量大于初始容量,老threshold也扩大为原来的两倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
//如果没有初始容量并且老threshold有容量则把threshold的值给新容量
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {// zero initial threshold signifies using defaults
//在都为空的情况下应该是第一次,给默认值
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//如果门槛为0
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//把新的门槛赋值过去
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//如果老table中有数据,需要把老table中的数据赋值给新的table
if (oldTab != null) {
//根据老容量进行遍历,把非空元素赋值
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
//如果e元素的下一个元素是null,则说明这个节点就他自己,直接赋值就可以
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//如果是一颗树,则拷贝树
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
//链表赋值,没有采用重新计算元素在数组位置,而是采用了一种 原始位置加原数组长度的方法计算得到的位置
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
//当元素扩容后,重新计算hash值的话,如图1,可以看出相当于原数值的最高位参与了计算,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置如图2 ,并由此jdk8中没有再重新计算hash值,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”
if ((e.hash & oldCap) == 0) {
//如果是0索引没变,把索引没变的元素都接到这上面,过程如图3,图4,图5
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
//这些是索引变的当前链表的元素都挂在这个上面
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//把坑没变的赋值到此
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//坑变的加上老的容量
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}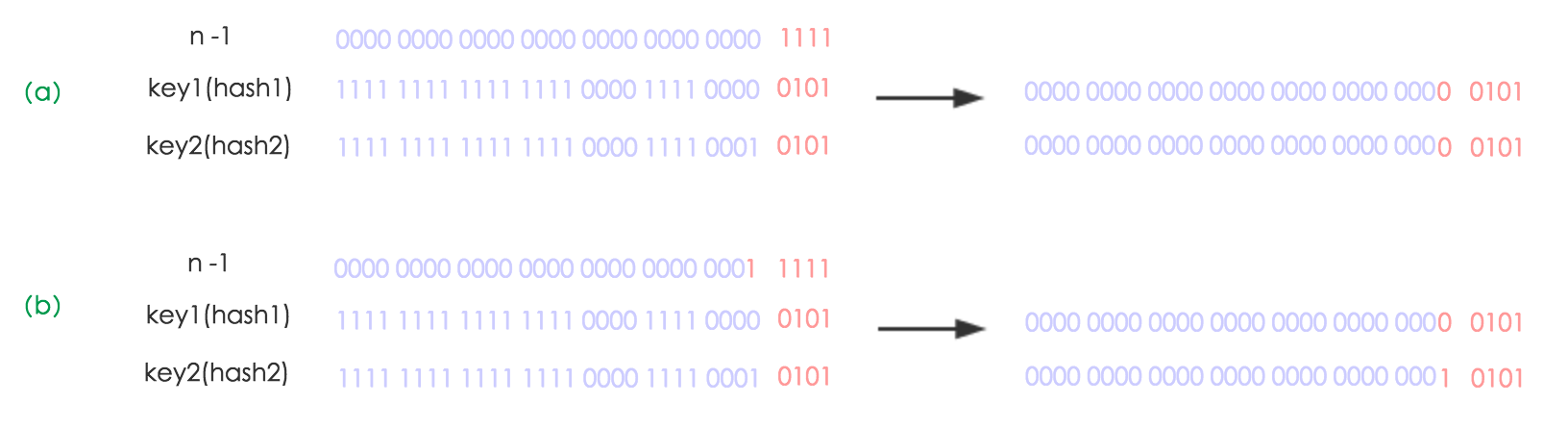
图 1

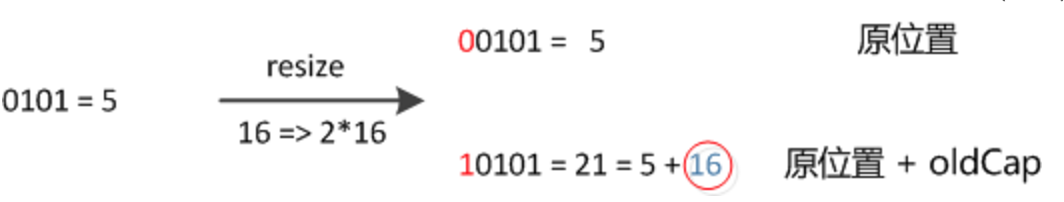
图 2

图 3
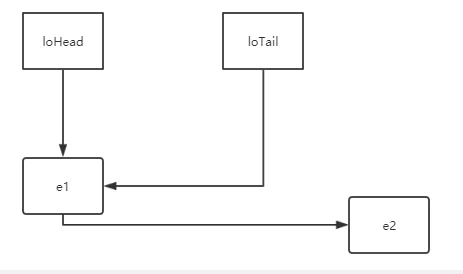
图4

图 5
ConcurrentHashMap

CAS+synchronized使锁的粒度更细
源码分析:

一个控制位标识量:负数代表正在扩容或者正在初始化;-1代表一个线程正在初始化,-n代表有n-1个线程正在扩容或初始化,正数或者0代表还没被初始化,因为是volatile,是线程可见的


- 不允许插入null,hashmap是可以的
- 如果有线程正在扩容,可以调用helptransfer进行协助扩容
- 进入else代表发生了hash碰撞,先锁住链表
put方法总体逻辑:

首先使用无锁操作插入头结点,失败则循环重试
如果头结点已经存在,则尝试获取头节点的同步锁,再进行操作
需要注意的点:
size和mappingCount方法的异同,两者计算是否准确?
多线程环境下如何扩容?
参考:
https://tech.meituan.com/2016/06/24/java-hashmap.html