MySQL中的order by limit中的坑
首先我们有一张表,如下所示
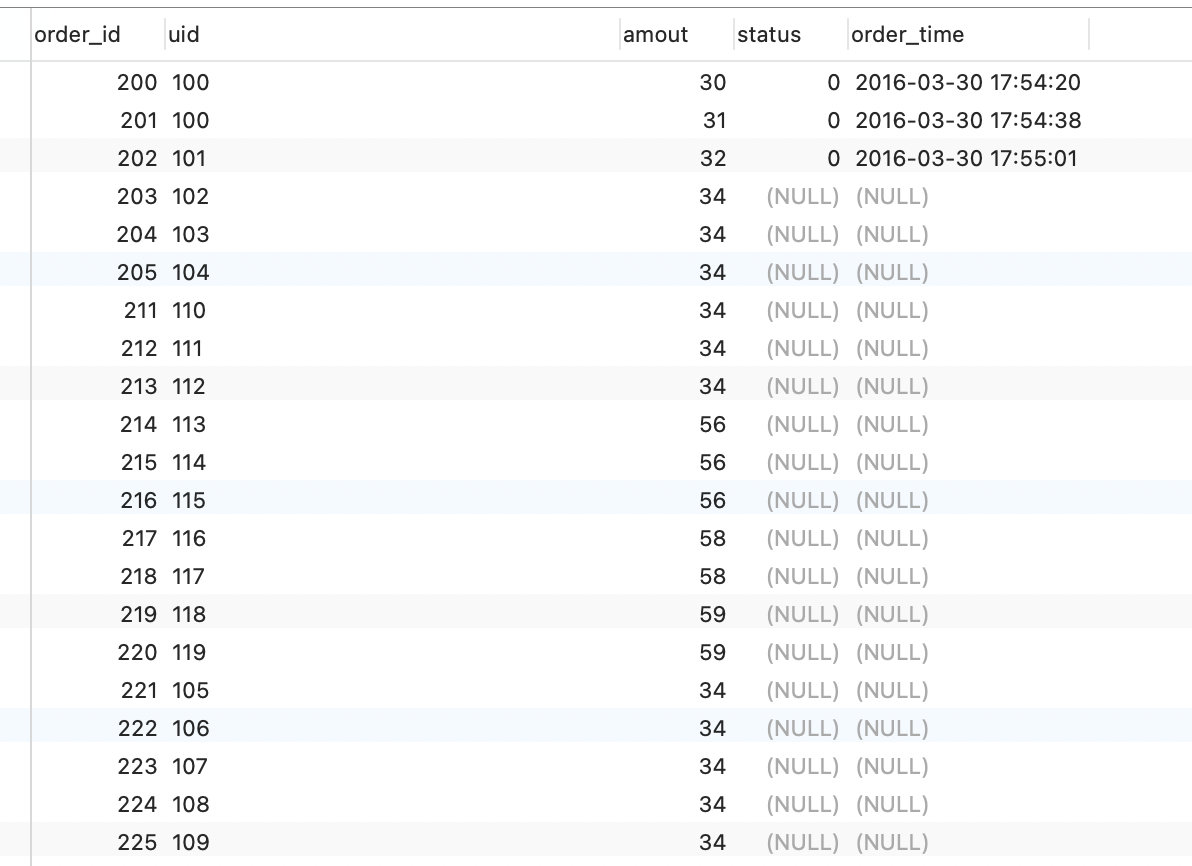
其中是按照amout进行升序排序的,此时我们想要查询按照amout升序排序前十条数据:
1 | |
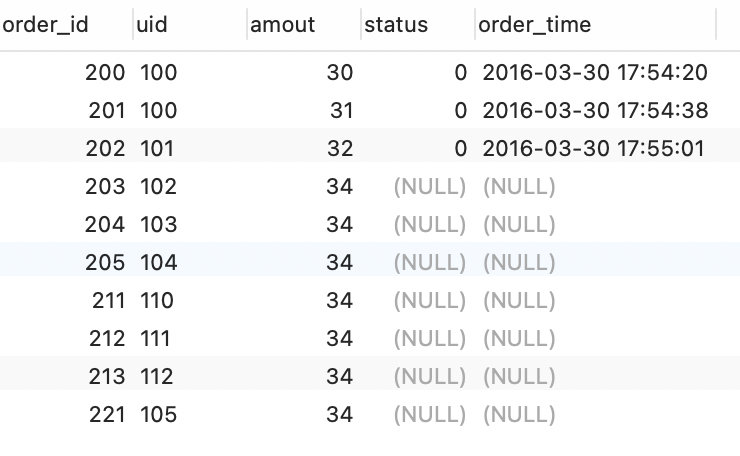
然后我们继续查询下一页的5条数据,sql如下:
1 | |
结果如下:
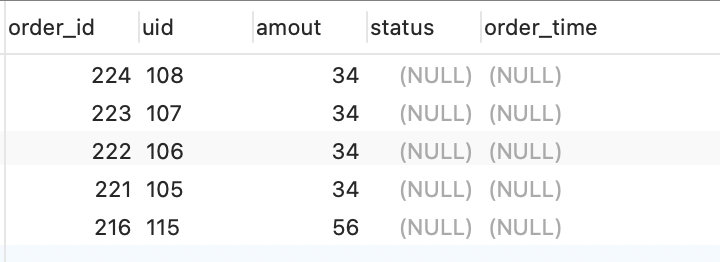
然后把两张图片放到一起比较一下
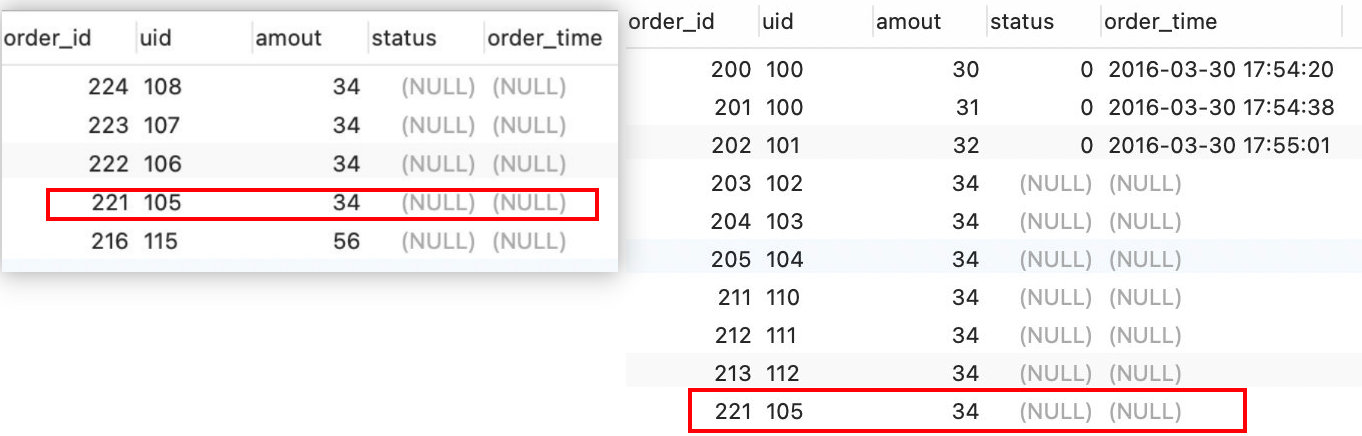
注意看红框中的数据,会发现id为221的这个数据重复出现了,这其实不符合我们所想的。
问题分析
那原因是什么呢?在这片官方文档中有解释:
1 | |
当混合使用limit和order by的时候,mysql会在查询到limit需要的行数后立刻返回,而不是进行整个的排序,然后把结果返回。
是不是不好理解,应该会有两个疑问:
第一个:没进行整个排序为什么会得出一个有序的结果;
第二个:为什么获取想要行数立即返回就会得到重复数据。
当我们知道order by amout是怎么排序的我们就可以解决上面的问题了。
查看一下执行计划:
1 | |

可以看到是没有走索引的,并且是使用filesort进行排序的,虽然这里写着filesort排序其实并不意味着是文件排序,有可能是内存排序,那我们就了解一下是如何排序的吧。
MySQL的排序
MySQL内部排序主要有三种方式:常规排序,优化排序和优化队列排序,主要涉及三种排序算法:快速排序,归并排序和堆排序
常规排序:
- 从表中获取满足where条件的记录
- 对于每条记录,将主键和排序键取出放入sort buffer中
- 对于sort buffer可以存放满足条件的,进行快速排序,保证sort buffer中的元素是有序的
- 当sort buffer被存满之后,需要把元素持久化到文件中,每次持久化文件的时候使用归并排序,使得文件中的元素是有序的,一直循环的执行完
- 然后捞取需要的结果返回给客户端
备注:对于这个sort buffer的大小sort_buffer_size 不同的版本是定义不同的,官方是这么说的
1 | |
大致意思是:对于8.0的来说,优化器根据需要的增量分配内存缓冲区,而不是像8.0之前那样分配一个固定的大小。
优化排序:
在常规排序中,我们sort buffer中装的是主键和排序键,这样的话需要先查出排序顺序,然后再查出需要字段给客户端,进行了两次IO,而优化排序是放入的需要查出的字段,这样的话就不需要第二次查询了,减少了 一次IO,但是这样会导致sort buffer中存的东西就少了。MySQL提供了参数max_length_for_sort_data,当排序元素小于这个值才会进行优化排序,否则进行常规排序。
优先队列排序:
在5.6版本之后针对order by limit M N进行了优化,虽然也需要所有元素排序(和整个进行排序不一样),但是只需要M+N的大小即可,上面我们说了:会在查询到limit需要的行数后立刻返回,这里用到的是堆排序。对于我们查询需要升序,直接采用大顶堆,只取上面的最小的N个元素就可以;对于降序,采用小顶堆,同理。我们之道堆排序是一种不稳定的排序,所以上述查出结果不一致的情况也可以很容易的理解了。
参考资料:
MySQL :: MySQL 5.7 Reference Manual :: 8.2.1.17 LIMIT Query Optimization
MySQL :: MySQL 8.0 Reference Manual :: 8.2.1.16 ORDER BY Optimization